
" 진화하는 AI 반도체 업계와 경쟁 "
인공지능(AI)의 두뇌는 반도체에요. 반도체 기술이 발전하면서 AI 성능도 부쩍 좋아지고 있는데요. 특히 AI 처리에 적합한 AI 반도체가 등장하면서 AI의 성능은 기하급수적으로 높아지고 있어요. 그 대표적인 예로 1999년 핫하게 등장한 엔비디아의 그래픽처리장치 GPU가 떠오르는데요!
아직까지 엔비디아를 대체할 수 있는 AI 반도체 시장은 없다고 평가되고 있는 한편, 다가올 2025년, 약 100조 원 시장이 예상되는 인공지능(AI) 두뇌를 선점하기 위한 반도체 기업의 치열한 경쟁이 펼쳐지고 있어요. 이때 등장한 NPU · TPU · IPU의 프로세서들은 엔비디아 GPU를 따라잡기 위해 고군분투 중이에요. 오늘은 차세대 AI 반도체 모델 소개와 함께 초거대 AI의 미래를 함께 그려보는 시간 가져보겠습니다 🤖
| GPU 정의, 다시 되돌아볼까요?
GPU(Graphic Processing Unit)은 대량의 데이터를 한 번에 처리할 수 있는 병렬처리 방식의 반도체에요. 엔비디아는 GPU를 처음에 게임, 영상과 같이 복잡한 그래픽을 처리하는 데 사용하려 개발했지만, 🔢AI에서 요구하는 방대한 양의 데이터를 연산 처리하면서부터 인공지능(AI)의 핵심 부품으로 떠올랐어요.
GPU는 명령어를 한 번에 하나씩 빠르게 직렬로 처리하는 중앙처리장치 CPU와 달리, 매우 빠른 속도를 통해 방대한 분량의 정보를 한 번에 처리 가능해요. 2016년 세상을 놀라게 했던 이세돌 바둑 기사와 구글 알파고는 176개의 엔비디아 GPU로 개발되었답니다.🤖
| AI 연산 프로세서 신경처리장치 NPU
이런 GPU의 대항마로 꼽히고 있는 차세대 반도체는 바로 NPU(Neural Processing Unit)에요. NPU는 그래픽 처리 용도로 개발됐던 GPU와 달리 처음부터 AI 연산을 목표로 개발된 반도체에요.
즉 딥러닝에 최적화되어 있고 전력, 효율, 면적, 수행 시간 등 AI 연산에 필요한 능력을 보유하고 있어, 점점 커지는 AI 모델과 많아지는 데이터를 처리할 수 있는 칩으로 꼽히고 있어요. NPU는 클라우드(가상 서버)나 인터넷 연결 없이도 AI 기능을 수행한다는 특징이 있는데요. AI 핸드폰, 소형 가전, 노트북 등에 다양한 영역에 적용됨으로써, GPU와 같이 온 디바이스 AI 구현에 핵심적이에요.
| 빠른 계산이 가능한 AI 텐서처리장치 TPU

TPU(Tensor Processing Unit)은 구글에서 개발한 NPU의 일종이에요. TPU도 NPU와 마찬가지로 인공 신경망 학습 및 추론 속도를 높이는 데에 특화된 칩인데요. TPU는 전통적인 Von Neumann 구조를 따르지 않고 독자적인 아키텍처로 구성되어 있어 NPU보다 빠른 병렬처리가 가능해요.
일례로 2017년 알파고의 최종 버전인 알파고 제로에 단 4개가 사용된 TPU는 GPU 176개로 개발된 알파고 초기 버전보다 학습 시간, 면적 등이 크게 개선도 됐고, 전력 소모도 10분의 1로 줄었다고 해요! 실제로 많은 초거대 AI 모델에서 구글의 TPU가 적용되며, 차세대 AI 반도체 모델이라며 칭하고 있답니다.
| AI에 특화된 지능처리장치 IPU

오늘 소개해 드릴 마지막 프로세서는 영국의 AI 반도체 스타트업 ‘그래픽코어’ 가 개발한 IPU(Infrastructure Processing Unit)입니다. IPU는 머신러닝(AI 데이터 학습)에 특화된 지능처리장치로, CPU나 GPU 등 기존 시스템 반도체보다 AI 데이터 처리 속도가 10배에서 최대 100까지 빠른 것으로 평가되고 있어요!
현재 마이크로소프트 MS에 AI 전용 반도체를 납품하기로 발표하면서 MS는 IPU를 자사 클라우드 컴퓨팅 플랫폼 애저(Azure)에 탑재해 고객에 좀 더 편리한 ai 개발 환경을 제공할 계획이라 밝혔어요.
MS 애저에 IPU가 적용되면, 사용자들은 애저 플랫폼 안에서 머신러닝이나 자연어처리(NLP) 등을 활용해 새로운 서비스나 제품을 쉽게 개발할 수 있게 돼요!🧑💻
|
* IPU-TPU-NPU-GPU 쉽게 이해하자! 🤖 NPU: 신경처리장치는 여러 데이터를 동시에 처리하고, 주로 이미지 인식, 음성 인식 등 인공지능 작업에 특화되어 있어요. 🤖 TPU: 딥러닝에 특화되어 있는 텐서처리장치는 아주 많은 숫자를 빠르게 계산하는 데 최적화되어 있어요. 🤖 IPU: 복잡한 인공지능 작업을 여러 개 동시 처리가 가능해요. 여러 데이터를 동시에 빨리 처리하는 GPU에서 조금 더 AI 작업에 특화되었어요. |
" 그럼에도 불구하고 왜 GPU일까요? "

위에서 살펴본 것처럼, 현재 많은 AI 반도체 기업에서는 엔비디아 GPU를 공공의 목표로 새로운 시장을 개척하기 위해 다양한 AI 칩을 개발 중에 있어요. 하지만, 당분간 엔비디아의 왕좌를 무너뜨리긴 쉽지 않다고 전망하는데요. 💻바로 엔비디아가 구축한 AI 생태계 때문인데요.
오늘날 많은 AI 개발자들이 알고리즘 개발에 사용하고 있는 플랫폼 ‘쿠다(CUDA)’는 현재 엔비디아 GPU에서만 동작하고 있어, 이미 해당 개발 시스템에 익숙해져 있는 개발자들은 다른 플랫폼을 사용하기 어려울 것으로 전망했어요.🧑💻
개발자들은 쿠다 툴킷을 사용해서 연산 집약적인 코드 부분을 GPU에서 실행될 수 있게 업데이트하고, C, C++, Python을 포함한 산업 표준 언어로 애플리케이션을 개발하고 함수를 호출할 수 있어요. 이러한 맥락에서 CUDA는 GPU를 효율적으로 활용할 수 있고 대규모 데이터 처리의 연산 속도를 높일 수 있게 도와줘요!
AI 생태계의 우월한 지배자, NVIDIA GPU와
매니지먼트솔루션 아스트라고

이처럼 CUDA 플랫폼은 오로지 NVIDIA GPU와 결합해서 사용할 수 있으니, 사실상 가장 빠른 AI 개발을 위해서는 GPU 사용이 정답이라고 볼 수 있어요. CUDA 쿠다를 통해 AI 모델의 학습 및 추론을 이행하셨다면, 해당 과정에 활력을 보태줄 GPU 매니지먼트 솔루션을 추가로 사용해 보는 건 어떨까요?


NVIDIA 공식 파트너사 씨이랩에서는 고효율의 ML 프로젝트로 향상시켜줄 수 있는 머신러닝 솔루션을 제공 중에 있어요. astrago 아스트라고에 서는 NVIDIA의 GPU를 효율적이고 편리하게 사용할 수 있는 GPU 분산 학습 및 스케줄러 기능을 제공해요. 크게는 AI 학습, 추론용으로 적합하게 활용하실 수 있어요.
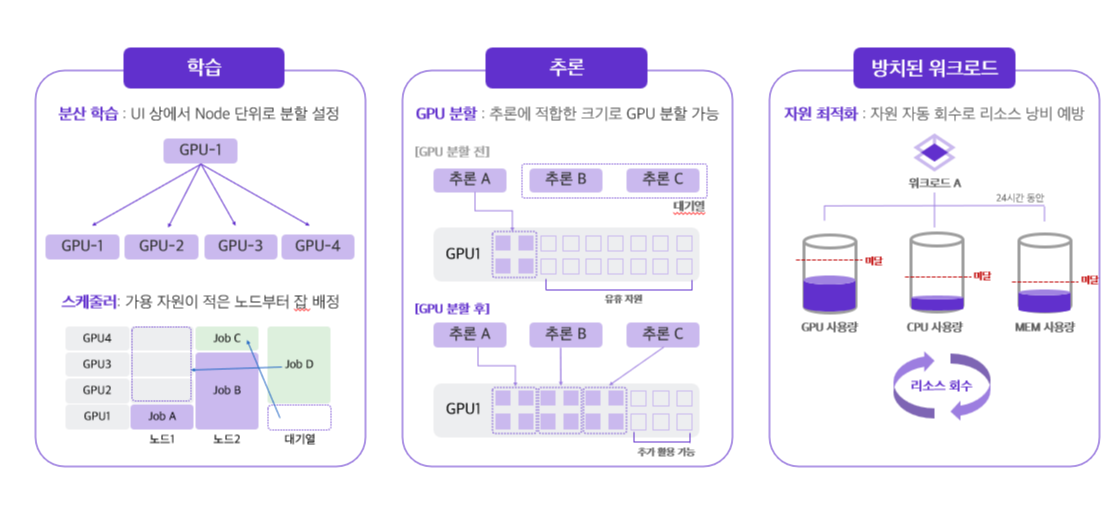
[AI 학습]
AI 프로젝트 시에는 대용량의 학습 데이터 및 모델을 기반으로 작업해야 해서 학습 속도를 높이는 것이 더욱 중요해지는데요. 이때 astrago의 분산학습 기능을 통해 워크 로드 생성 시에 UI 상에서 노드 단위로 GPU 분할을 설정함으로써 학습 속도를 가속화할 수 있어요. 그뿐만 아니라 워크 로드가 생성된 이후에는 스케줄러가 가용자원이 적은 노드부터 잡을 배정하여 GPU 사용 효율을 극대화할 수 있어요. 😆

[AI 추론]
반면, 머신러닝 모델이 새로운 데이터에서 결론을 도출하는 AI 추론 시에는 학습에 비해 적은 용량이 필요하지만 모델을 더욱 효과적으로 훈련하고 미세 조정할 수 있도록 튜닝하는 과정이 필요한데요! 이를 위해 아스트라고에서는 추론을 효율적으로 진행할 수 있는 GPU 분할 및 모델 관리 기능을 지원해요.
GPU 분할을 통해 추론 워크 로드에 적합한 크기로 GPU를 분할하여, 컴퓨팅 자원을 분할 전보다 활용률을 극대화할 수 있는데요. 더불어, 모델 관리 기능을 통해 이제까지 배포된 모델의 버저닝을 일괄적으로 확인함으로 모델 추론부터 관리까지 astrago에서 편리하게 일원화하여 사용할 수 있어요.😄
AI 머신러닝 솔루션 아스트라고는 손쉬운 관리와 편리한 개발을 관리할 수 있는 사용자 편의 중심의 UI/UX를 제공하고 있어, 효율적인 인프라 구축이 가능해요. 다양한 AI 프로젝트를 관리하기 위한 최적의 머신러닝 솔루션, Astrago와 함께해보세요!

'AstraGo' 카테고리의 다른 글
| 머신러닝 딥러닝 모델의 성능 향상을 위한 파인 튜닝 전략 (0) | 2024.08.09 |
|---|---|
| LLM 개발을 더 간편하게! LangChain 랭체인 개념과 작동원리 (3) | 2024.08.08 |
| 복잡한 잡스케줄을 효율적으로 관리하고 싶다면, 일괄처리작업 Batch Job(배치잡) (2) | 2024.07.29 |
| 대규모 데이터도 고속 처리하는 고성능 컴퓨팅 HPC (0) | 2024.07.29 |
| 유연한 로드밸런싱을 위한 쿠버네티스 멀티 클러스터 환경과 요건 (1) | 2024.07.19 |



