
안녕하세요 AI 영상 분석 전문 씨이랩입니다😊 현재 많은 기업과 조직들에서는 AI의 역량을 활용해 자체 온프레미스 데이터 센터에서 직원 생산성을 높이고, 혁신적인 AI 기반 사용자 경험을 창출하는데 많은 노력을 가하고 있어요.
이러한 AI 흐름에 따라 어디에서나 실행할 수 있는 AI 서비스가 주목받고 있어요. 대표적으로 NVIDIA NIM(NVIDIA Inference Microsoft)을 통해 다양한 기능을 활용할 수 있는데요! 이번 콘텐츠에서 NVIDIA NIM 소개와 함께 업계 동향을 짧게 소개해 드리는 시간을 가져볼게요.
NVIDIA NIM의 탄생 배경과 그 가치

많은 기업이 AI를 거의 필수적으로 도입을 하여 솔루션과 비즈니스 모델에 사용을 하고 있는 것을 쉽게 볼 수 있는데요. 문제는 외부 또는 해외에서 제공하는 AI API를 사용하였을 때 비용, 레이턴시, 컴플라이언스 문제를 맞닥뜨리게 된다는 것이에요. 이러한 문제점을 인지한 엔비디아에서는 기업 AI 애플리케이션을 더욱 효율적으로 배포할 수 있도록 도와주고자, NVIDIA GPU에서 AI 모델을 최적화된 컨테이너로 제공하며, 어디에서나 실행할 수 있는 추론 마이크로 서비스인 NIM을 출시하게 되었어요.
엔비디아에서 출시한 NIM 이란, AI 모델을 최적화된 컨테이너로 제공하는 추론 마이크로 서비스예요. 이동성과 제어를 위해 구축되어 다양한 인프라 어디에서나 쉽게 모델을 배포할 수 있고, API를 통해 AI 모델에 액세스하여 AI 애플리케이션 개발을 간소화할 수 있어요. NIM의 등장으로 전 세계 약 2,800만 명의 개발자들이 NVIDIA NIM을 이용해 단 몇 분 안에 클라우드, 데이터센터, 워크스테이션 등에서 AI 애플리케이션을 쉽게 구축할 수 있게 되었답니다 :) 😮🙌
AI 도입에 따라 많은 기업에서 겪고 있는 문제들 |
토큰 당 가격으로 측정되는
다소 부담스러운 비용
|
Model
|
Pricing
|
Pricing With Batch API*
|
|
GPT-4o
|
$5.00/1M input tokens
|
$2.50/1M input tokens
|
|
$15.00/1M output tokens
|
$7.50/1M output tokens
|
|
|
GPT-4o-2024-08-26
|
$2.50/1M input tokens
|
$1.25/1M input tokens
|
|
$10.00/1M output tokens
|
$5.00/1M output tokens
|
|
|
GPT-4o-2024-05-13
|
$5.00/1M input tokens
|
$2.50/1M input tokens
|
|
$15.00/1M output tokens
|
$7.50/1M output tokens
|
현재 OpenAI에서 발표한 GPT-4o의 금액표는 상기와 같아요. 큰 규모의 기업이나 장기간 해당 서비스를 사용해야 하는 고객 입장에서는 토큰 당 가격을 측정하여 매겨지는 비용이 비교적 큰 부담으로 다가올 수밖에 없는데요. 이러한 이유로 기업에서는 Chat GPT-4o의 70% 성능만 갖춘 비교적 저렴한 AI 모델을 구매하여 사용하는 것을 선호하고 있는 추세에요.
애플리케이션 성능을 좌우하는
대기 지연시간 레이턴시
 |
 |
|
|
속도 (초당 출력 토큰, 높을수록 좋음)
|
가격 (1M 토큰 당 USD: 낮을수록 좋음)
|
|
GPT-4o와 타사 오픈소스 AI의 속도 및 가격을 비교한 결과, 속도 영역에서 GPT-4o의 경우, 초당 105개의 토큰을 출력함으로써 12개 오픈소스 AI 중 6위를 차지했어요. 가장 높은 가격대를 고려했을 때, GPT-4o의 속도가 빠르지 않다는 것을 알 수 있었어요.
만약, 국내에서 미국에 있는 GPT-4o 서버를 끌어와 사용한다고 가정하자면, 엄청난 물리적인 거리로 인해 레이턴시가 발생할 수밖에 없겠죠.
개인정보 보호, 데이터 사용의 투명성
알고리즘의 공정성에 따라 화두 되는
컴플라이언스 이슈
외부 API에 대한 보안 세팅이 제대로 되어있지 않을 경우, 회사 내부에 기밀문서 혹은 데이터가 침해당할 가능성이 있어요. 대표적으로 가장 흔히 발생하는 컴플라이언스 이슈가 보안 규정 준수 위반 및 데이터 유출이에요.
이때 NVIDIA NIM (Inference Microservice) 컴플라이언스는 기업들이 인공지능 기술을 효율적으로 관리하고, 관련 규정을 준수하도록 지원하게 설계되어 있어, AI의 투명성과 윤리를 강조하며, 데이터 관리 및 AI 모델의 책임성을 증진시켜줘요.
다양한 이슈 대응 방안을 제공하고 있는 NIM
|
그렇다면 앞서 언급된 비용, 레이턴시 컴플라이언스 등의
이슈를 NIM은 어떻게 해결하고 있을까요?

1️⃣ 경제적인 비용
Chat GPT 4o와 NVIDIA NIM을 각각 데이터센터 환경에서 사용한다고 가정한 후 비용을 측정해 보겠습니다.
- 사용 인원 : 1,000 명
- 사용 빈도 : 1인당 하루에 10회 대화
- 대화 길이 : 1회 대회당 750 토큰 (질문과 답변 포함)
위에서 언급했듯이 $5.00 / 1M input tokens 와 $15.00 / 1M output tokens 을 적용했을 때, 연간 chat GPT 4o의 사용 비용은 총 $18,900 (한화 기준 24,570,000원)인데요. 반면, NIM을 탑재한 엔비디아 AI 엔터프라이즈의 가격은 GPU 당 연간 $4천500달러 (약 602만 원)로 훨씬 비용의 우위를 선점하게 된다는 것을 알 수 있었어요.
2️⃣ 하드웨어· LLM 모델 자동 최적화
NIM은 LLM의 성능을 최대로 끌어내기 위해 자동으로 하드웨어 및 LLM 모델에 맞는 최적화를 진행하면 어떻게 될까요?
- 첫 번째 토큰까지의 시간(TTFT) : 모델에 대한 초기 추론 요청과 첫 번째 토큰 반환 사이의 지연 시간
- 토큰 간 지연 시간(ITL) : 첫 번째 토큰 이후 각 토큰 사이의 지연 시간
- 총 처리량 : NIM에서 초당 생성되는 총 토큰 수
TensorRT-LLM이 다양한 NVIDIA GPU 모델에 대한 최적화 버전을 지원하게 되면, NIM 백엔드에는 지연 시간을 최소화하거나 처리량을 최대화하는 프로필이 포함되어 있어, 사용자 환경에 맞는 최적화 모델 성능을 이끌어내요. NIM은 사용자의 하드웨어 환경을 진단하여 automatic profile 목록에서 가장 적합한 항목을 선택하도록 처리하고, 최적화 버전을 지원하게 돼요. 대략적인 프로세스는 아래와 같아요.
ⓐ Compatibility check : GPU의 모델 종류와 수에 따라 실행할 수 없는 프로필을 필터링
ⓑ Backend : TensorRT-LLM 또는 vLLM 중 하나로, 모두 실행 가능한 경우 최적화된 TensorRT-LLM 프로필이 vLLM 보다 선호됨
ⓒ Precision : 정밀도가 낮은 프로필을 선택할 경우, FP16보다 FP8을 우선하여 선택 진행
ⓓ Optimization Profile : 선택 가능할 경우, throughoutput 최적화보다 latency-optimized 프로필을 선택 진행
ⓔ Tensor Parallelism : 병렬 처리 값이 높은 프로필이 선호되며. 4개의 GPU보다 8개의 GPU가 필요할 경우 우선순위로 선택됨
|
Detected 2 compatible profile(s).
Valid profile: 751382df4272eafc83f541f364d61b35aed9cce8c7b0c869269cea5a366cd08c (tensorrt_llm-A100-fp16-tp1-throughput) on GPUs [0] Valid profile: 8835c31752fbc67ef658b20a9f78e056914fdef0660206d82f252d62fd96064d (vllm-fp16-tp1) on GPUs [0] Selected profile: 751382df4272eafc83f541f364d61b35aed9cce8c7b0c869269cea5a366cd08c (tensorrt_llm-A100-fp16-tp1-throughput) Profile metadata: precision: fp16 Profile metadata: feat_lora: false Profile metadata: gpu: A100 Profile metadata: gpu_device: 20b2:10de Profile metadata: tp: 1 Profile metadata: llm_engine: tensorrt_llm Profile metadata: pp: 1 Profile metadata: profile: throughput |
위와 같은 Selection 과정은 예시 코드 로그로 실행돼요. NIM의 내재화된 최적화 프로필 항목이 기존 Chat GPT-4o처럼 LLM 모델을 사용했을 때의 레이턴시 문제를 해결해 줘요!
3️⃣ 자체 사내 환경에서 구동
NVIDIA NIM은 Hosted API 서버 사용이 가져올 수 있는 컴플라이언스 이슈를 고객의 자체 서버 환경에서 NIM을 구동할 수 있게 만들면서 해결책을 가져왔어요. 이 덕분에 조직은 모델을 자체 호스팅 하며 데이터와 개인 정보 보호 및 보안 규정을 준수할 수 있게 되었답니다.

NIM에서 제공하는 SOTA 모델과 NIM의 전제 조건 |
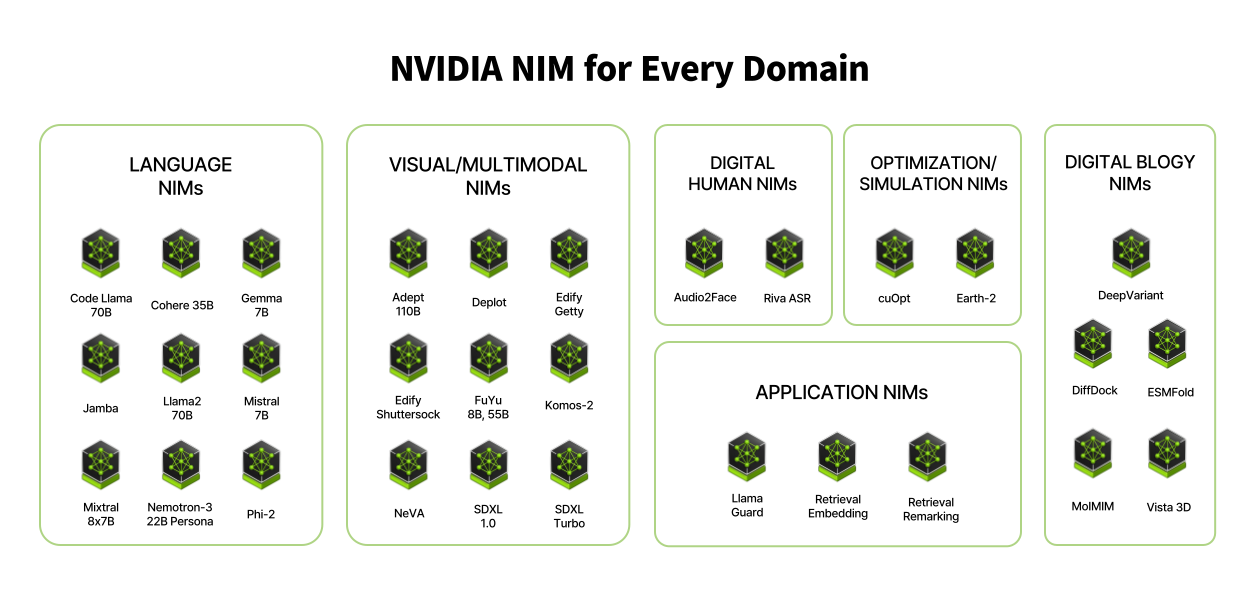
NVIDIA NIM은 SOTA AI 모델을 제공하여, 클라우드나 데이터센터에서 배포하고 데이터를 안전하게 유지하는 데 도움을 주고 있어요. 하지만 이렇게 비용 합리적이고 최적의 모델을 손쉽게 접근할 수 있도록 도와주는 NIM에도 제약 사항이 있는데요.😐
가장 큰 조건은 NVIDIA의 AI Enterprise 라이선스를 보유하고, 사용하는 GPU가 NVIDIA의 제품이어야만 해요. 더불어, NIM의 SOTA 모델을 사용하기 위해서는 특정하여 최적화시킨 GPU 모델을 가지고 있어야 바로 접근하여 사용이 가능하죠. 😥
L40s에 최적화된 SOTA 모델을 가지고 있는 유저로 예를 들어볼게요. 유저가 L40s 없이 사용하는 것도 가능하지만, 직접 모델을 빌드 하는 과정을 거치게 되죠. 그 외의 하드웨어는 최소 16GB의 RAM., 최신 x86_64 아키텍처 기반의 CPU, 고사양의 스토리지 등이 권장되고 있어요.
[ NIM 활용해서 모델 5분 만에 배포하는 방법 ]
1️⃣ API 카탈로그 접근을 위한 build.nvidia.com 접속
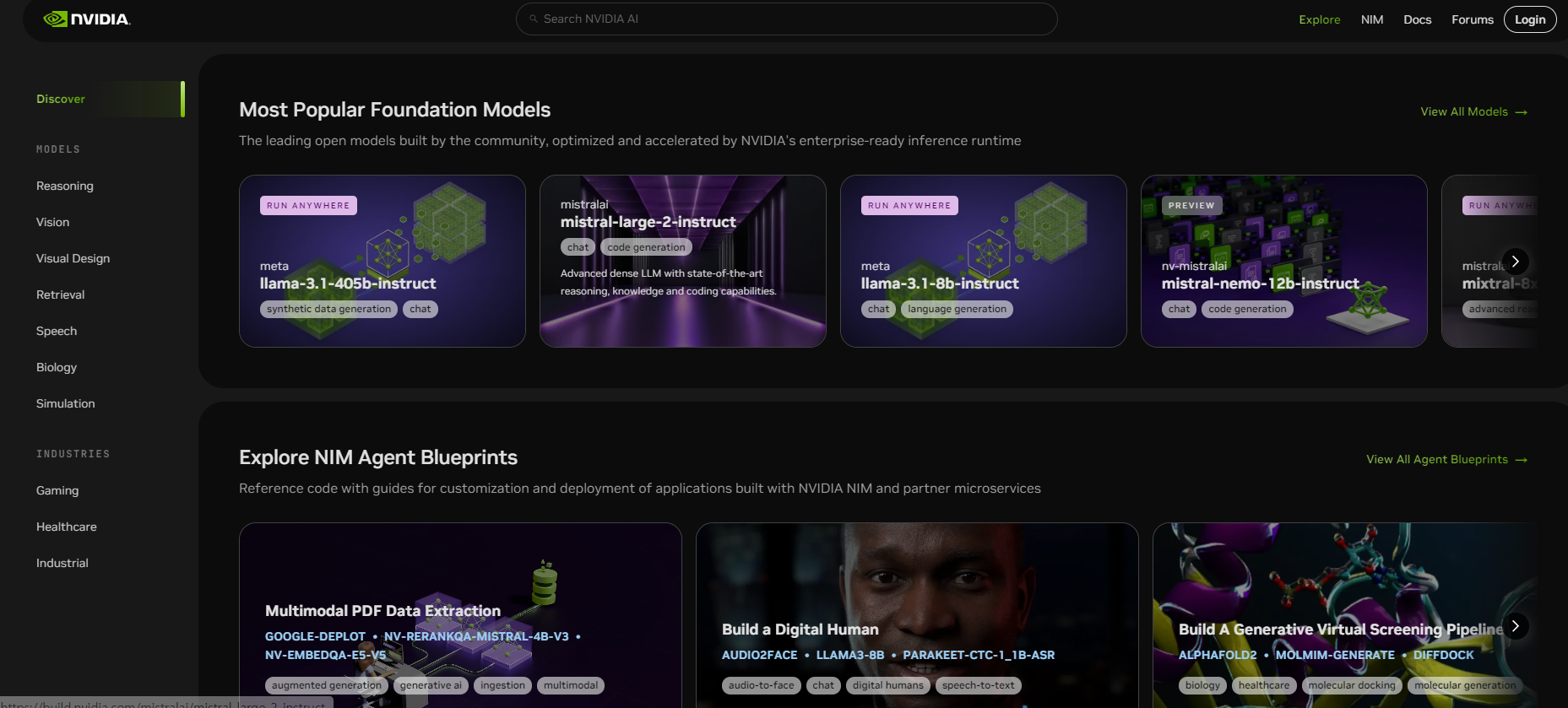
2️⃣사용하고자 하는 모델의 성능 테스트 진행
: 화면에서 NIM 컨테이너를 pull 하는 방법에 대한 가이드라인을 제공하고 사용자의 환경에서 즉시 실행할 수 있어요.
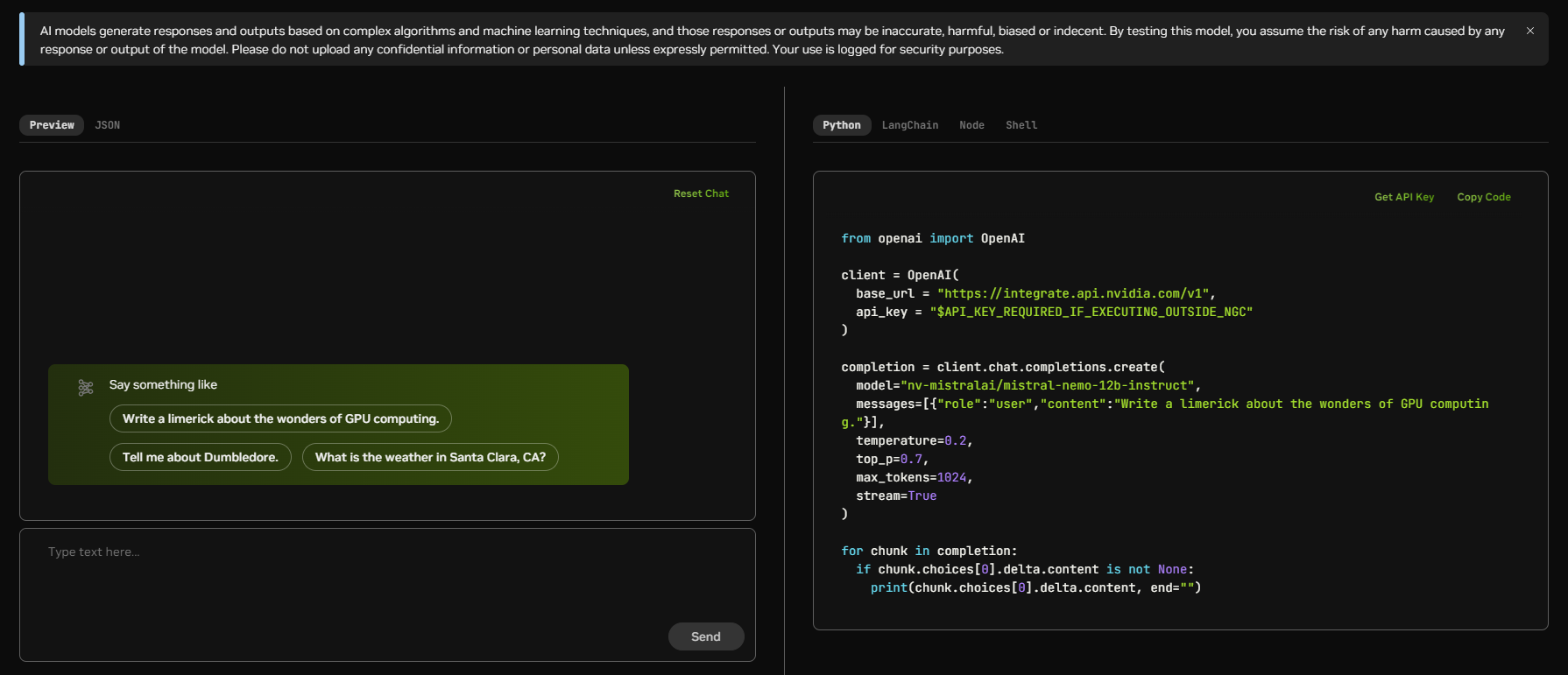
3️⃣ 엔비디아 컨테이너 레지스트리에 로그인하기
: 로그인을 위해서는 Docker Engine과 Docker Command Line 툴이 사전 설치되어 있어야 합니다.
|
(base) nealv@s4124-0013:/tmp$ docker login nvcr.io
User name: $oauthtoken Password: WARNING! Your password will be stored unencrypted in /home/nealv/.docker/config.json. Configure a credential helper to remove this warning.See http://docs.docker.com/engine/reference/commandline/login/#credentials-store Login Succeeded (base) nealv@s4124-0013:/tmp$ export NGC-API KEY^C (base) nealv@s4124-0013:tmp$ export LOCAL-NIM-CACHE=/tmp/.cache/nim (base) nealv@s4124-0013:tmp$ docker run -it --rm \ --gpus all \ --shm-size=16GB \ -e NGC_API_KEY \ -v "$LOCAL_NIM_CHANCE :/opt/nim/. cache" \ -u $(id -u) \ -p 8000 : 8000 \ nvcr.io/nim/meta/llamma3-8b-instruct:1.0.0 |
4️⃣ NIM이 준비되었는지 확인 후 request 발신
|
(base) nealv@s4124-0013:/tmp$
(base) nealv@s4124-0013:/tmp$ curl -X 'POST' \ 'http://0.0.0.0:0000/v1/chat/completions; \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "model" : "meta/llama3-8b-instruct", "message" : [{"role":"user", "content" : "write a limerick about the wonders of GPU Computing. "}] "max_tokens":64 }' {"id" : "cmpl-1f7f0639109145a0ad33ae878f44d49f", "object":"chat.completion", "created":1720729409, "model":"meta"/llama3-8b-instruct","choices":[{in 0, "message":{"role":"assistant","content":"there once a GPU so fine, \ nwhose computing powews were truly divine. \ nIt processed with frair ex tasks in the air,\ nAnd solved problem in a timeframe sublime!"}, "logprobs":null,"finish_reason":"stop","stop_reason":128009}],"usage": |
이 4가지 과정을 거치면 사용자가 선택한 AI 모델을 가지고 NIM을 활용해 모델을 배포할 수 있게 돼요.
NIM 출시 이후 동종 업계의 대응 방안 |
AI 서버 시장을 양분하고 있는 HPE, Dell 역시 NIM 지원 방안을 공개하며 기업 고객의 니즈에 대응하고 있어요.
Dell의 NIM 지원 방안
Dell은 NIM 업데이트를 통해 PowerScale를 모델 캐시로 사용하도록 권장하고 있어요. PowerScale 캐시에 모델을 저장하면 모든 서버 또는 여러 클러스터에서 모델을 재사용할 수 있기 때문이에요.

해당사항은 기업에서 특정 모델을 사용자가 정의할 경우, 모델 재사용에서 큰 장점이 되는데요. 이는 여러 서버에서 모델을 사용할 수 있으므로 애플리케이션을 수평적으로 확장할 수 있고, 잠재적 성능 또한 향상시킬 수 있어요.
PowerScale를 모델 캐시로 사용하기 위해 NIM을 업데이트하는 방법은 다음과 같아요. (NIM에서 사용자가 Llama 3 8B를 선택할 경우)
1️⃣먼저, 컨테이너 이름과 이미지 이름을 내보내요.
|
$ export CONTAINER_NAME=meta-llama3-8b-instruct
$ export IMG_NAME="nvcr.io/nim/meta/llama3-8b-instruct:1.0.0" |
2️⃣ 이후 PowerScale에서 캐시로 사용될 디렉터리를 만들고 해당 디렉터리를 내보내요.
|
$ export LOCAL_NIM_CACHE=/aipsf810/project-helix/NIM/nim
$ mkdir -p "$LOCAL_NIM_CACHE" |
3️⃣ 이제 이러한 환경 변수로 컨테이너를 실행합니다.
|
INFO 06-05 14:57:25.508 server.py:82] Started server process [32]
INFO 06-05 14:57:25.509 on.py:48] Waiting for application startup. INFO 06-05 14:57:25.518 on.py:62] Application startup complete. INFO 06-05 14:57:25.519 server.py:214] Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit) |
위 3가지 단계만 거치면 PowerScale에 캐시 된 Llama 3 8B를 사용하여 LLM에 대한 NIM을 성공적으로 배포할 수 있습니다 :) 😄
HPE Private LLM 구축 방안
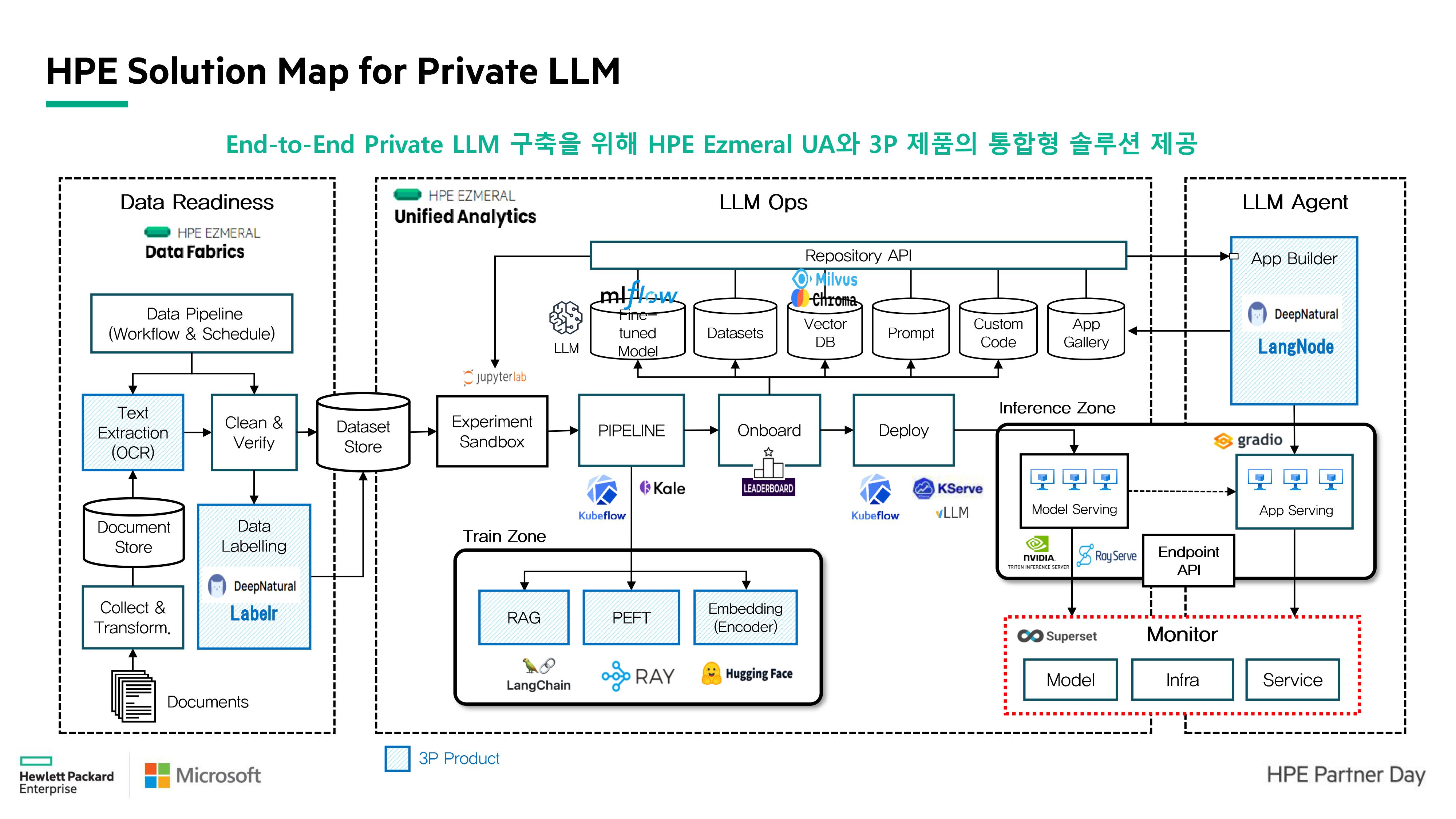
HPE 또한 사용자들의 편의를 위한 SOTA 모델을 지원하며, 사전 학습된 모델을 지원하는 'Private LLM Solution'을 출시했어요.
Private LLM PoC Kit의 장점은 한국어에 특화된 오픈소스 Foundation Model 을 다수 제공해요. 더불어, 고객사가 선택한 LLM으로 변경이 가능한 점도 중요한 장점 중 하나에요! Private LLM PoC Kit에서 제공하는 대표적인 K-LLM은 Solar (10.7B), Bllossom (LLaMA-3 기반 한국어 지원, 테디 썸) 등이 있답니다 :)
이처럼 엔비디아 NIM 출시에 따라, 동종 업계에 있는 주요 IT기업들도 NVIDIA의 서비스를 한 층 더 잘 활용할 수 있는 방법과 유사한 서비스를 제공하고 있는데요. 앞으로도 Dell과 HPE와 같은 기업들의 노력으로 AI 도입을 위한 장벽이 낮아지면서, 더 많은 AI 활용 서비스를 출시할 것으로 기대됩니다! 그때까지 글로벌 주요 파트너사 씨이랩에서 한발 앞선 소식과 정보들을 전달해 드리겠습니다 😉💗

'AstraGo' 카테고리의 다른 글
| Vision 분야를 주도하는 객체 알고리즘 YOLO시리즈 알아보기 (7) | 2024.10.14 |
|---|---|
| AI 인프라 내 HW+SW 통합 관리 가능한 AstraGo HPE OneView (0) | 2024.09.24 |
| AI 워크로드 내 추론 과정을 간소화시켜줄 최적의 솔루션 NVIDIA TRITON (5) | 2024.09.02 |
| 딥러닝 모델을 최적화하는 방법 'AI 모델 경량화' (1) | 2024.08.29 |
| AI 프로젝트에 GPU 활용을 극대화시켜줄 AstraGo 주요 기능과 고객 사례 (1) | 2024.08.23 |



